![]()
Extended Kalman Filter for online SLAM
Simultaneous localization and mapping (SLAM) is a chicken-and-egg problem. It tries to solve the problem of localizing the robot in a map while building the map.
Localization : Estimate the robot path, i.e., a sequence of poses and locations, \(x_{0:T} = {x_{0}, x_{1}, x_{2}, ..., x_{T}}\) where $1:T$ denotes the timestep from 1 to T and $x_0$ is the initial robot pose.
Mapping : Build a map of the environment, $m$
Online SLAM
In contrast to full SLAM, which estimate the full robot path and the map at once, online SLAM estimates only the most recent robot pose together with the map at each time step t. \(p(x_t, m \vert z_{1:t}, u_{1:t})\) which can be done by marginalizing out the previous poses (recursively): \(p(x_{t}, m | z_{1:t}, u_{1:t}) = \int_{x_0} ... \int_{x_{t-1}} p(x_{0:t}, m | z_{1:t}, u_{1:t}) dx_{t-1} ... dx_{0}\)
 |
|---|
| Graphical model Online SLAM [Probabilistic robotics] |
Bayes Filter
Bayes filter provides a recursive tool to estimate the map and the robot poses given the robot odometry and observations. Bayes filter consists of two steps: the prediction step and the correction step.
Prediction step : Predict the expected robot pose given the previous robot pose and robot odometry
Correction step : Correct the predicted robot pose given the robot observations and update the map
The two steps take place in turns recursively until the all robot poses are estimated and the map is constructed.
Extended Kalman Filter
Bayes filter plays well with SLAM because of its capability of modeling the uncertainty with certain assumptions. The typical assumptions are:
- The measurement noise, in both robot odometry and robot observations, are Gaussian
- The robot motion model as well as observation model are linear
That boils down the category of Bayes filter to the Kalman filter and it’s variants. The most commonly used variants is the Extended Kalman Filter (EKF) where the robot motion model and observation model are not necessarily linear. But it still requires the local linearity from those two models so that a first-order Taylor expansion can be performed to linearize the motion model and the observation model.
A 2-dimentional example
Now the fun part comes. Assume a robot lives in a 2D world. It is capable of rotate and translate in the world. Other than the robot, there are also a fixed number of asterisks planted in the same 2D world. The robot could observe them but cannot move them. We are provided the noisy measurements about the robot moves and observations and the goal is to build a map of this 2D world and localize the robot in this map at each time step.
using Pkg
Pkg.add(PackageSpec(url="https://github.com/JihongJu/SlamTutorial.jl", rev="master"))
import SlamTutorial:
make_canvas, draw_2d_robot,
example2d_landmarks
fig, ax = make_canvas(-1, -1, 12, 12)
landmarks = example2d_landmarks()
ax.scatter(landmarks[:, 1], landmarks[:, 2], marker="*", color="r") # Draw asterisks
draw_2d_robot(ax, [3, 2.5, π/4])

2-element Array{Any,1}:
PyObject <matplotlib.collections.PathCollection object at 0x7f2c4202a0b8>
PyObject <matplotlib.collections.PathCollection object at 0x7f2c4202a4a8>
The motion model: standard odometry model
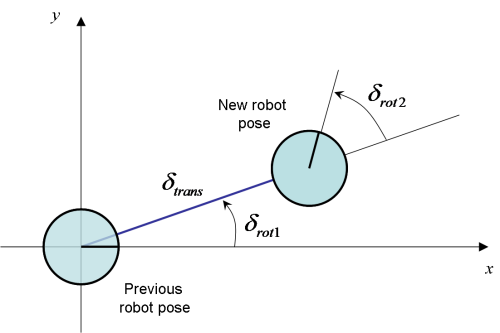 |
|---|
| Robot motion model [Figure from www.mrpt.org] |
The robot odometry readings at each time step is: \(u = (\delta_{rot1}, \delta_{trans}, \delta_{rot2})\)
The robot motion update is given by:
\[\begin{pmatrix} x' \\ y' \\ \theta' \\ \end{pmatrix} = \begin{pmatrix} x \\ y \\ \theta \\ \end{pmatrix} + \begin{pmatrix} \delta_{trans} \cos(\theta + \delta_{rot1}) \\ \delta_{trans} \sin(\theta + \delta_{rot1}) \\ \delta_{rot1} + \delta_{rot2} \end{pmatrix}\]struct Odometry
rot1::Float32
trans::Float32
rot2::Float32
end
function standard_odometry_model(pose, odometry)
rx, ry, rθ = pose
direction = rθ + odometry.rot1
rx += odometry.trans * cos(direction)
ry += odometry.trans * sin(direction)
rθ += odometry.rot1 + odometry.rot2
rθ = rem2pi(rθ, RoundNearest) # Round to [-π, π]
return [rx, ry, rθ]
end
standard_odometry_model (generic function with 1 method)
The observation model: Range-bearing observation
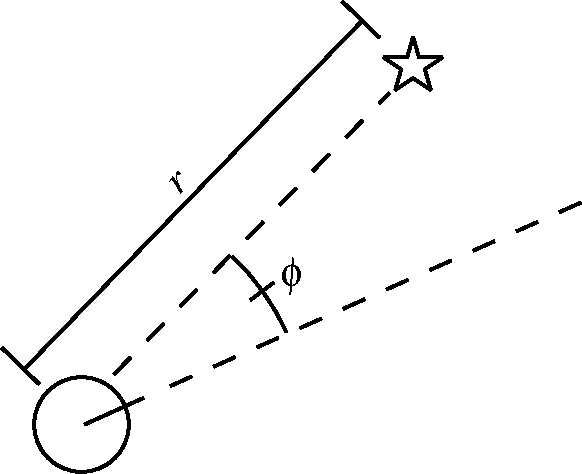 |
|---|
| Robot observation model [Montemerlo, Michael, et al.] |
Assume the robot can associate the observed asterisk (landmark) with its unique id, the sensor reading for the i-th asterisk at time step t is:
\[z_t^i = (r_t^i, \phi_t^i)^T\]This leads to the prediction of the i-th asterisk position at time step t:
\[\begin{pmatrix} \bar \mu_{j,x} \\ \bar \mu_{j,y} \\ \end{pmatrix} = \begin{pmatrix} \bar \mu_{t,x} \\ \bar \mu_{t,y} \\ \end{pmatrix} + \begin{pmatrix} r_t^i \cos(\phi_t^i + \bar \mu_{t, \theta}) \\ r_t^i \sin(\phi_t^i + \bar \mu_{t, \theta}) \\ \end{pmatrix}\]struct RangeBearing
landmark_id::Int8
range::Float32
bearing::Float32
end
function range_bearing_model(robot_pose, range_bearing)
rx, ry, rθ = robot_pose
range, bearing = range_bearing.range, range_bearing.bearing
mx = rx + range * cos(bearing + rθ)
my = ry + range * sin(bearing + rθ)
return [mx, my]
end
range_bearing_model (generic function with 1 method)
State representation for EKF
State represents an estimation, a.k.a, a belief, of the robot’s pose $(x,y,\theta)$ and locations of n landmarks:
\[x_t = (x, y, \theta, m_{1,x}, m_{1,y}, \dots, m_{n, x}, m_{n, y})\]Assuming the robot pose and the landmark locations are both Gaussian distribution, the probabilistic representation of the state is the mean and the variance:
\[\mu = (x, y, \theta, m_{1,x}, m_{1,y}, \dots, m_{n, x}, m_{n, y})\] \[\Sigma = \begin{pmatrix} \sigma_{xx} & \sigma_{xy} & \sigma_{x\theta} & | & \sigma_{x m_{1,x}} & \sigma_{x m_{1,y}} & \ldots & \sigma_{x m_{n,y}} & \sigma_{x m_{n,y}} \\ \sigma_{yx} & \sigma_{yy} & \sigma_{y\theta} & | & \sigma_{y m_{1,x}} & \sigma_{y m_{1,y}} & \ldots & \sigma_{y m_{n,y}} & \sigma_{y m_{n,y}} \\ \sigma_{\theta x} & \sigma_{\theta y} & \sigma_{\theta \theta} & | & \sigma_{\theta m_{1,x}} & \sigma_{\theta m_{1,y}} & \ldots & \sigma_{\theta m_{n,y}} & \sigma_{\theta m_{n,y}} \\ - & - & - & | & - & - & - & - & - \\ \sigma_{m_{1,x}x} & \sigma_{m_{1,x}y} & \sigma_{m_{1,x}\theta} & | & \sigma_{m_{1,x} m_{1,x}} & \sigma_{m_{1,x} m_{1,y}} & \ldots & \sigma_{m_{1,x} m_{n,y}} & \sigma_{m_{1,x} m_{n,y}} \\ \sigma_{m_{1,y}x} & \sigma_{m_{1,y}y} & \sigma_{m_{1,y}\theta} & | & \sigma_{m_{1,y} m_{1,x}} & \sigma_{m_{1,y} m_{1,y}} & \ldots & \sigma_{m_{1,y} m_{n,y}} & \sigma_{m_{1,y} m_{n,y}} \\ \vdots & \vdots & \vdots & | & \vdots & \vdots & \ddots & \vdots & \vdots\\ \sigma_{m_{n,x}x} & \sigma_{m_{n,x}y} & \sigma_{m_{n,x}\theta} & | & \sigma_{m_{n,x} m_{1,x}} & \sigma_{m_{n,x} m_{1,y}} & \ldots & \sigma_{m_{n,x} m_{n,y}} & \sigma_{m_{n,x} m_{n,y}} \\ \sigma_{m_{n,y}x} & \sigma_{m_{n,y}y} & \sigma_{m_{n,y}\theta} & | & \sigma_{m_{n,y} m_{1,x}} & \sigma_{m_{n,y} m_{1,y}} & \ldots & \sigma_{m_{n,y} m_{n,y}} & \sigma_{m_{n,y} m_{n,y}} \\ \end{pmatrix}\]Or, in simpler form,
\[\mu = \begin{pmatrix} x \\ m \\ \end{pmatrix}\] \[\Sigma = \begin{pmatrix} \Sigma_{xx} & \Sigma_{xm} \\ \Sigma_{mx} & \Sigma_{mm} \\ \end{pmatrix}\]State Initialization
The mean and covariance matrix of the state are initialized with:
\[\mu_0 = \begin{pmatrix} 0 \\ 0 \\ \vdots \\ 0 \\ \end{pmatrix}\] \[\Sigma_0 = \begin{pmatrix} 0 & 0 & 0 & 0 & \ldots & 0 \\ 0 & 0 & 0 & 0 & \ldots & 0 \\ 0 & 0 & 0 & 0 & \ldots & 0 \\ 0 & 0 & 0 & \infty & \ldots & 0 \\ 0 & 0 & 0 & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & 0 & \ldots & \infty \\ \end{pmatrix}\]using LinearAlgebra
mutable struct Belief
mean::Vector{Union{Float32, Missing}}
covariance::Matrix{Float32}
end
function belief_init(num_landmarks)
μ = Vector{Union{Float32, Missing}}(missing, 3 + 2*num_landmarks)
μ[1:3] .= 0
Σ = zeros(Float32, 3+2*num_landmarks, 3+2*num_landmarks)
Σ[diagind(Σ)[1:3]] .= 0
Σ[diagind(Σ)[4:end]] .= 1000
return Belief(μ, Symmetric(Σ))
end
belief_init (generic function with 1 method)
Prediction step
function prediction_step(belief, odometry)
# Compute the new mu based on the noise-free (odometry-based) motion model
rx, ry, rθ = belief.mean[1:3]
belief.mean[1:3] = standard_odometry_model([rx, ry, rθ], odometry)
# Compute the 3x3 Jacobian Gx of the motion model
Gx = Matrix{Float32}(I, 3, 3)
heading = rθ + odometry.rot1
Gx[1, 3] -= odometry.trans * sin(heading) # ∂x'/∂θ
Gx[2, 3] += odometry.trans * cos(heading) # ∂y'/∂θ
# Motion noise
Rx = Diagonal{Float32}([0.1, 0.1, 0.01])
# Compute the predicted sigma after incorporating the motion
Σxx = belief.covariance[1:3, 1:3]
Σxm = belief.covariance[1:3, 4:end]
Σ = Matrix(belief.covariance)
Σ[1:3, 1:3] = Gx * Σxx * Gx' + Rx
Σ[1:3, 4:end] = Gx * Σxm
belief.covariance = Symmetric(Σ)
end
prediction_step (generic function with 1 method)
Correction step
function correction_step(belief, range_bearings)
rx, ry, rθ = belief.mean[1:3]
num_range_bearings = length(range_bearings)
num_dim_state = length(belief.mean)
H = Matrix{Float32}(undef, 2 * num_range_bearings, num_dim_state) # Jacobian matrix ∂ẑ/∂(rx,ry)
zs, ẑs = [], [] # true and predicted observations
for (i, range_bearing) in enumerate(range_bearings)
mid = range_bearing.landmark_id
if ismissing(belief.mean[2*mid+2])
# Initialize its pose in mu based on the measurement and the current robot pose
mx, my = range_bearing_model([rx, ry, rθ], range_bearing)
belief.mean[2*mid+2:2*mid+3] = [mx, my]
end
# Add the landmark measurement to the Z vector
zs = [zs; range_bearing.range; range_bearing.bearing]
# Use the current estimate of the landmark pose
# to compute the corresponding expected measurement in z̄:
mx, my = belief.mean[2*mid+2:2*mid+3]
δ = [mx - rx, my - ry]
q = dot(δ, δ)
sqrtq = sqrt(q)
ẑs = [ẑs; sqrtq; atan(δ[2], δ[1]) - rθ]
# Compute the Jacobian Hi of the measurement function h for this observation
δx, δy = δ
Hi = zeros(Float32, 2, num_dim_state)
Hi[1:2, 1:3] = [
-sqrtq * δx -sqrtq * δy 0;
δy -δx -q
] / q
Hi[1:2, 2*mid+2:2*mid+3] = [
sqrtq * δx sqrtq * δy;
-δy δx
] / q
# Augment H with the new Hi
H[2*i-1:2*i, 1:end] = Hi
end
# Construct the sensor noise matrix Q
Q = Diagonal{Float32}(ones(2 * num_range_bearings) * 0.01)
# Compute the Kalman gain K
K = belief.covariance * H' * inv(H * belief.covariance * H' + Q)
# Compute the difference between the expected and recorded measurements.
Δz = zs - ẑs
# Normalize the bearings
Δz[2:2:end] = map(bearing->rem2pi(bearing, RoundNearest), Δz[2:2:end])
# Finish the correction step by computing the new mu and sigma.
belief.mean += K * Δz
I = Diagonal{Float32}(ones(num_dim_state))
belief.covariance = Symmetric((I - K * H) * belief.covariance)
# Normalize theta in the robot pose.
belief.mean[3] = rem2pi(belief.mean[3], RoundNearest)
end
correction_step (generic function with 1 method)
Get started
Finally here we are. Let’s get it started. A robot wanders into the asterisk forest.
import SlamTutorial:
make_canvas, make_animation, animate_kalman_state,
example2d_landmarks, example2d_sensor_data
landmarks = example2d_landmarks()
num_landmarks = size(landmarks, 1)
odometries, range_bearingss = example2d_sensor_data()
believes = []
belief = belief_init(num_landmarks)
for t in 1:length(odometries)
prediction_step(belief, odometries[t])
correction_step(belief, range_bearingss[t])
push!(believes, deepcopy(belief))
end
canvas = make_canvas(-1, -1, 11, 11)
HTML(animate_kalman_state(canvas, believes, range_bearingss, landmarks).to_jshtml())